Per capire davvero il SEO e come funziona l’algoritmo di Google, dovete conoscere e capire come funzionano le due menti di GoogleBot, ovvero lo spider ed il crawler. Questa infografica vi spiega l’essenziale e le differenze tra i 2 software:
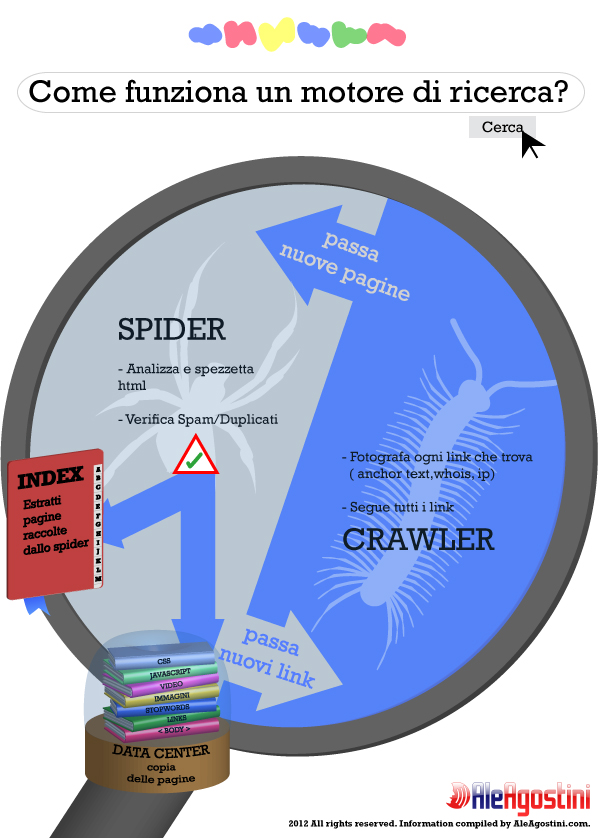
- Spider
Il lavoro principale dello spider è farsi una copia dell’Html delle pagine di un sito web, suddividerle in parti, farne il controllo spam, salvare un estratto sintetico dei contenuti che andrà nell’Index ed in alcuni casi copiare una foto completa della pagina che andrà nella parte dati ( Copia Cache). Per sapere come trovare la copia cache delle tue pagine guarda il post sui comandi avanzati.
- Crawler
La funzione del Crawler è analizzare e seguire i link forniti dallo Spider nella sua opera di catalogazione delle pagine. Tutti i link seguiti dal crawler sono analizzati in profondità in base ad una serie di parametri (anchor text, proprietario del dominio, whois etc) che permettono a Google di capire il valore SEO reale di ogni link e quindi eventuali penalty ( per saperne di più sulle penalizzazioni Google scarica la checklist). Se il crawler trova nuove pagine non presenti nell’indice dello spider, li comunica allo spider stesso che ricomincia la scansione e indicizzazione.